|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| • |
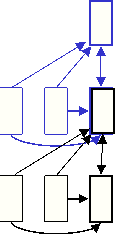
Treat the hidden
activities of the first level
|
|
|
TRBM as the data
for the second-level
|
|
|
TRBM.
|
|
|
– |
So
when we learn the second level, we
|
|
|
get
connections across time in the first
|
|
|
hidden
layer.
|
|
| • |
After greedy
learning, we can generate from
|
|
the composite
model
|
|
|
– |
First,
generate from the top-level model
|
|
|
by
using alternating Gibbs sampling
|
|
|
between
the current hiddens and
|
|
|
visibles
of the top-level model, using the
|
|
|
dynamic
biases created by the previous
|
|
|
top-level
visibles.
|
|
|
– |
Then
do a single top-down pass through
|
|
|
the
lower layers, but using the inputs
|
|
|
coming
from earlier states of each layer.
|
|