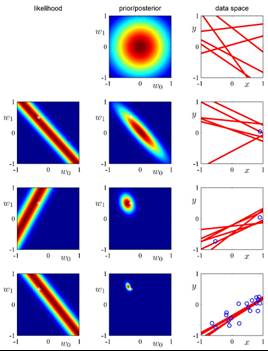
•
With no data we
sample lines from
the prior.
•
With 20 data
points, the prior
has little effect