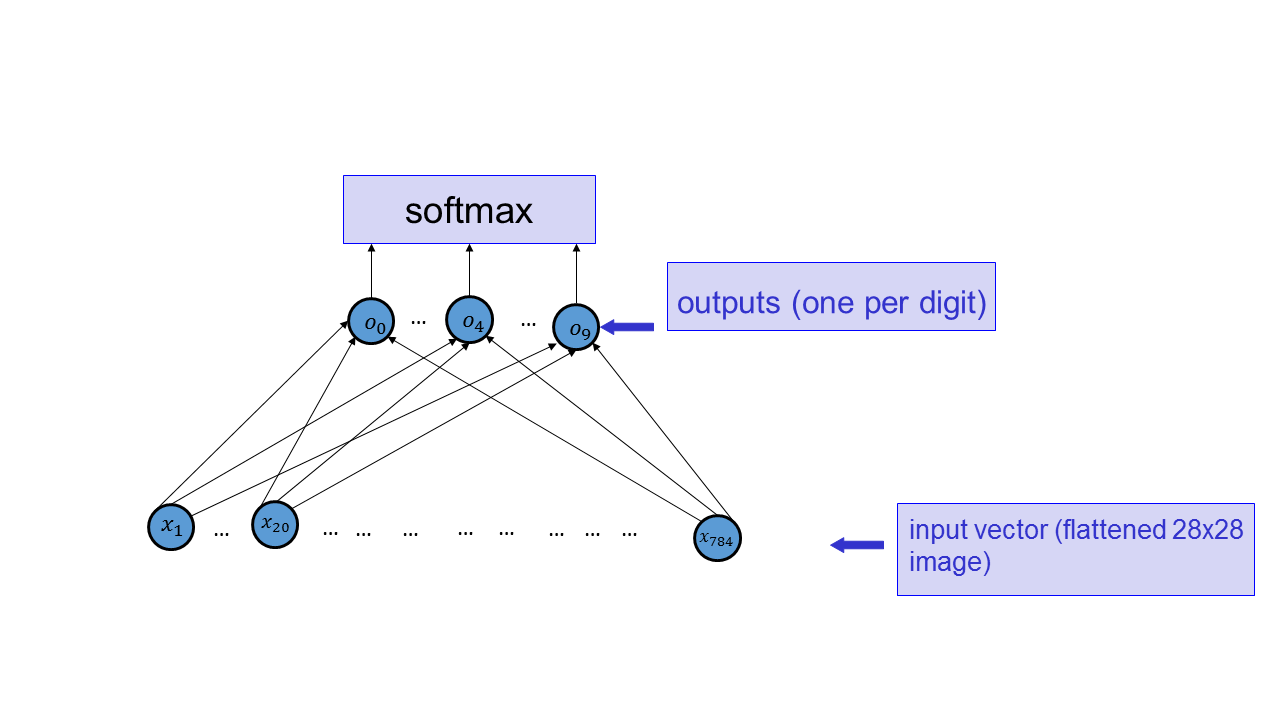
 For this project, you will build and train two systems for digit classification: one neural network and one linear classifier. Note: for the classifiers and settings suggested in this project, overfitting is not a significant problem; we therefore forego requiring that you have a validation set. You can nevertheless use one at your discretion.
For this project, you will build and train two systems for digit classification: one neural network and one linear classifier. Note: for the classifiers and settings suggested in this project, overfitting is not a significant problem; we therefore forego requiring that you have a validation set. You can nevertheless use one at your discretion.
You will work with the MNIST dataset. The dataset is available in easy-to-read-in format here, with the digits already seprated into a training and a test set. I recommend you divide the data by 255.0 (note: the .0 is important) so that it's in the range 0..1.
I am providing some code here (data: snapshot50.pkl). The code is not meant to be run as is. I am simply providing some functions and code snippets to make your life easier. Despite the fact that most of the code is more directly usable for the second half of the project, it should also help with the first half, and you should read and understand the code before you attempt Part 3.
In your report, include 10 images of each of the digits. You may find matplotlib's subplot useful.
Implement a function that computes the network below.
The o's here should simply be linear combinations of the x's (that is, the activation function is the identity). Specifically, use o_i = SUM_j w_ji x_j + b_i. Include the listing of your implementation (i.e., the source code for the function; options for how to do that in LaTeX are here) in your report for this Part.
For this project, we will be using the the sum of the negative log-probabilities of the correct answer for the N training cases under consideration as the cost function. (I.e., the negative log-likelihood of the training set.)
Implement a function that computes the gradient of this cost function with respect to the parameters of the network (W and b), for a given subset of training cases. Include a listing of your implementation in your report for this Part. You can, but do not have to, vectorize your code.
Verify that you are computing the gradient in Part 3 correctly by computing it both using your function and using a finite-difference approximation for several coordinates of the W and b. In your report for this Part, include the listing of the code that you used and the output of the code (which should include both your precise gradient and the approximation).
You will not get credit for Part 3 if you do not attempt Part 4
Write code to minimize your the cost function using mini-batch gradient descent, using the training set provided to you. You should be able to obtain test classification performance of over 91% correct classification (anything above 89% is OK). A learning rate of about 0.01 and batch sizes of 50 should work well.
For the training and the test set, graph the negative-log probability of the correct answer and correct classification rate versus the number of updates to the weights and biases during training. (I.e., plot the learning curves.)
In your report, display 20 digits which were classified correctly, and 10 digits from the test set which were classified incorrectly.
You can visualize what the network is doing by visualizing the W's as if they were digits. Visualize each of the set of W's that connect to o0, the set of W's that connect to o1, etc, with each w_ji displayed at an appropriate pixel. For example, for the W's that connect to o3, I obtain the following image.
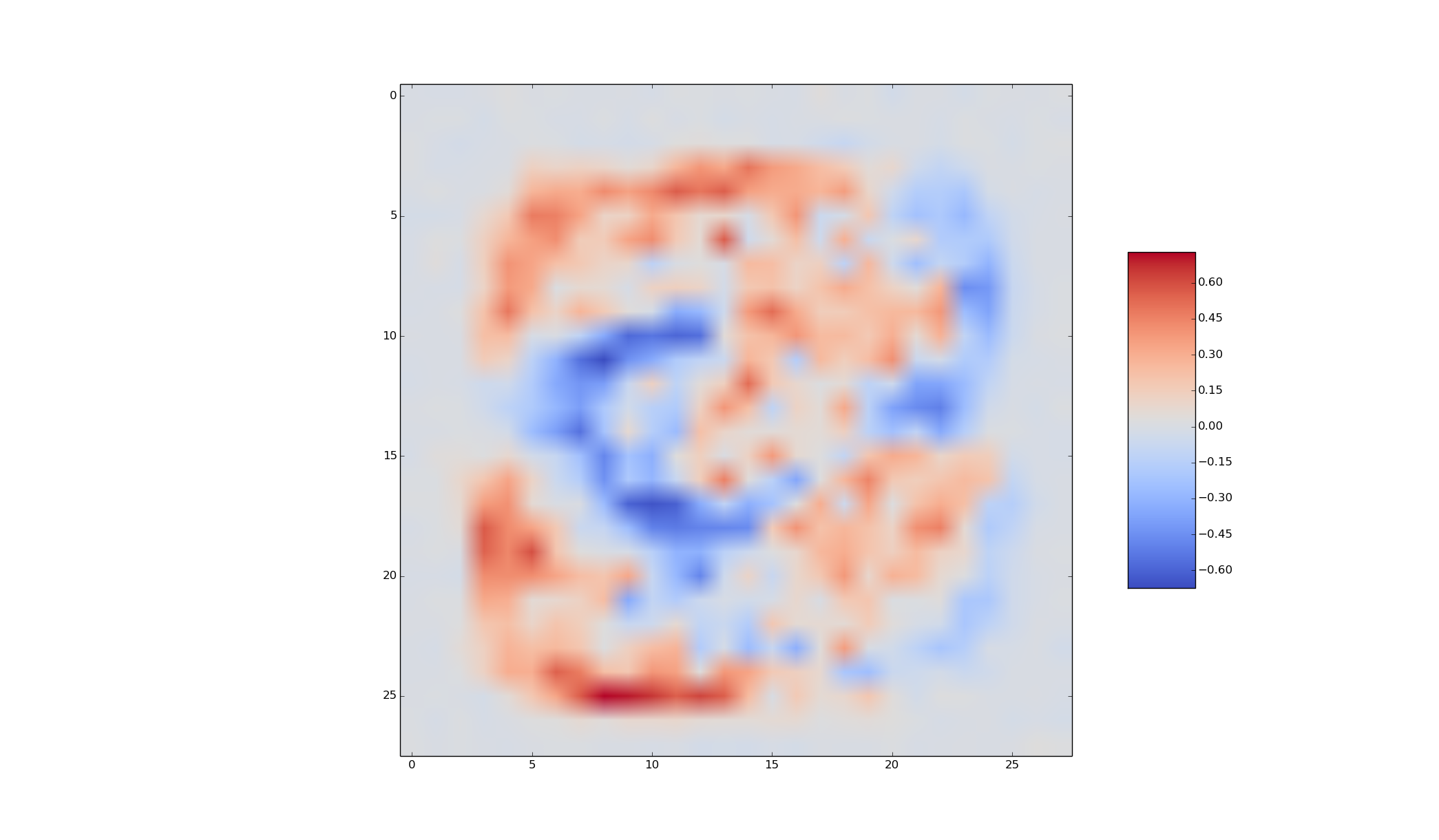
Comment on the visualization of the weights that you obtained. (One or two sentences are enough: just tell us what you see.)
For this part, you will implement a neural network with a hidden layer for digit classification. Specifically, you should implement the network sketched below, using tanh activation functions and 300 hidden units.
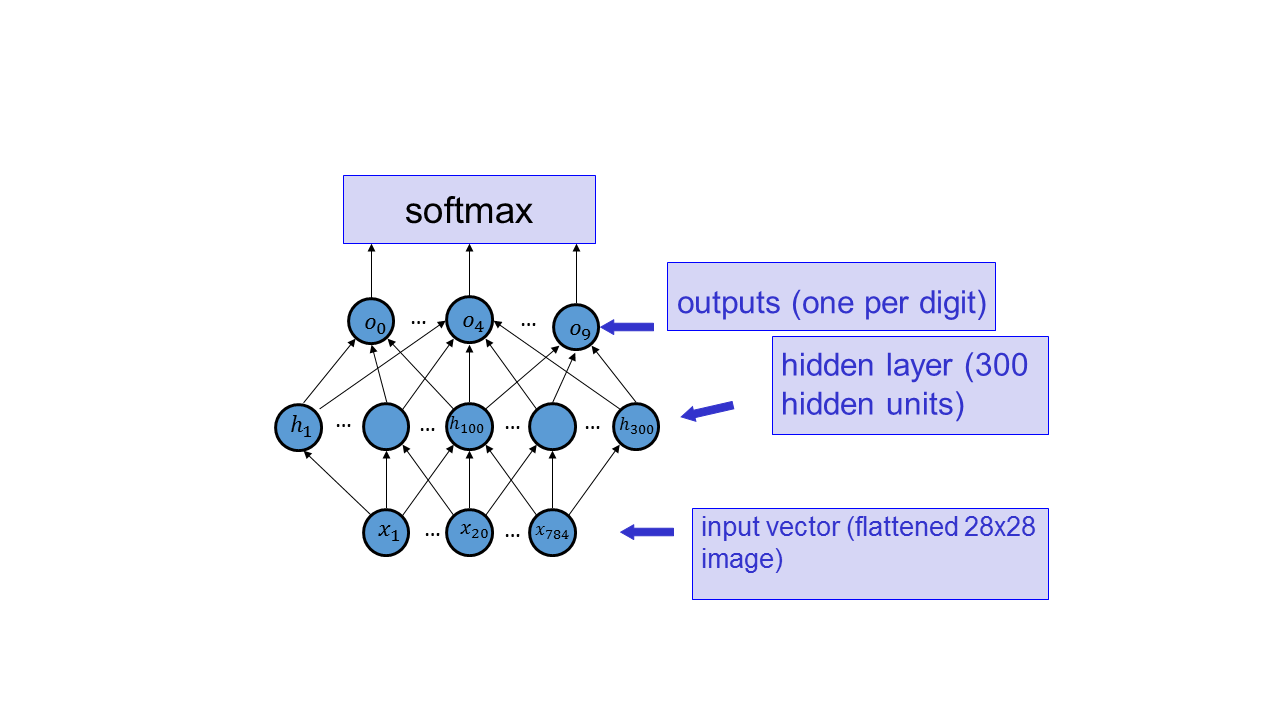
We have already provided you with a function that computes the network. For this part, implement a function that computes the gradient of the negative log probability of the correct answer function, computed for a set of training examples, with respect to the network parameters. The code must be vectorized. Include the listing of the code, as well, as an explanation for why each line of the code actually works (I.e., provide the computation using sigma notation, and briefly show how the matrix algebra accomplishes the same thing. For this part, you may include scanned neatly handwritten explanation included in the pdf, if you like, although you are encouraged to use LaTeX.)
Verify that you are computing the gradient in Part 7 correctly by computing it both using your function and using a finite-difference approximation for several coordinates of the W and b. In your report for this Part, include the listing of the code that you used and the output of the code (which should include both your precise gradient and the approximation).
You will not get credit for Part 7 if you do not attempt Part 8
Write code to minimize your the cost function using mini-batch gradient descent, using the training set provided to you. You should be able to obtain test classification performance of over 95% correct classification. A learning rate of about 0.01 and batch sizes of 50 should work well.
For the training and the test set, graph the negative log probability of the correct answer cost function and correct classification rate versus the number of updates to the weights and biases during training. (I.e., plot the learning curves.)
In your report, display 20 digits which were classified correctly, and 10 digits from the test set which were classified incorrectly.
You can visualize what the network is doing by visualizing the W's connected to the hidden layer as if they were digits. Select two interesting W's to visualize (out of the total of 300) and explain what you think they are accomplishing. (The explanations should be different for the different W's).
For example, for one of the W connecting the inputs to the hidden layer, I obtain the following:
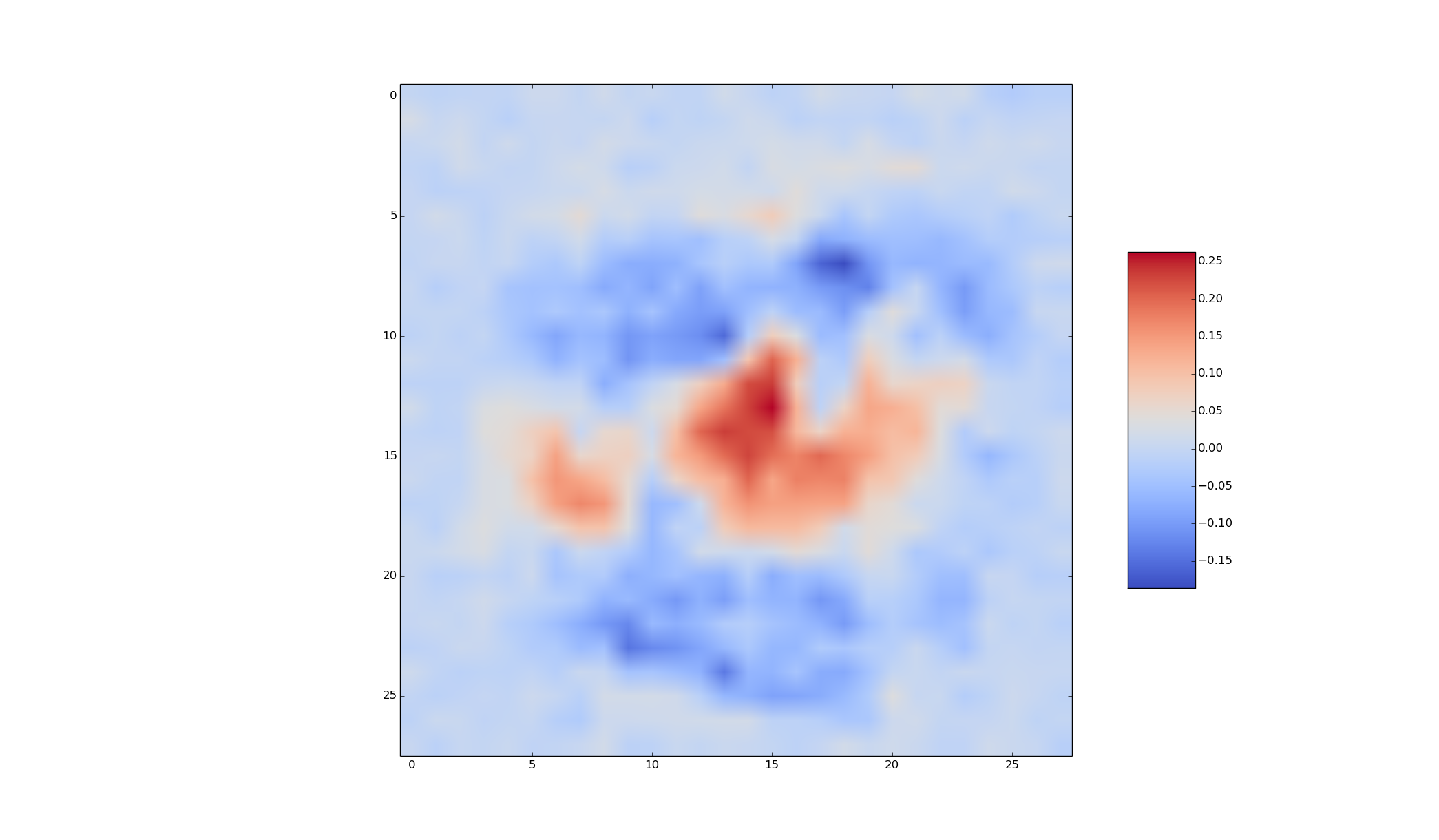
The weights connecting the hidden unit that corresonds to this W to the output units are: [-0.17553222, 0.09433381, -0.75548565, 0.13704424, 0.17520368, -0.02166308, 0.15751396, -0.31243968, 0.12079471, 0.66215879].
The project should be implemented using Python 2 and should run on CDF. Your report should be in PDF format. You should use LaTeX to generate the report, and submit the .tex file as well. A sample template is on the course website. You will submit three files: digits.py, digits.tex, and digits.pdf. You can submit other Python files as well: we should have all the code that's needed to run your experiments.
Reproducibility counts! We should be able to obtain all the graphs and figures in your report by running your code. Submissions that are not reproducible will not receive full marks. If your graphs/reported numbers cannot be reproduced by running the code, you may be docked up to 20%. (Of course, if the code is simply incomplete, you may lose even more.) Suggestion: if you are using randomness anywhere, use numpy.random.seed(). We are fine with minor variations that arise due to the differences between your system and CDF. For visualizing weights, it would be fine if we obtained different images that what you obtained when we run your code, but we should obtain some images.
You must use LaTeX to generate the report. LaTeX is the tool used to generate virtually all technical reports and research papers in machine learning, and students report that after they get used to writing reports in LaTeX, they start using LaTeX for all their course reports. In addition, using LaTeX facilitates the production of reproducible results.
Using my code
You are free to use any of the code available from the course website.
Important: