



The ALE phrase structure processing component is loosely based on a combination of the functionality of the PATR-II system and the DCG system built into Prolog. Roughly speaking, ALE provides a system like that of DCGs, with two primary differences. The first difference stems from the fact that ALE uses attribute-value logic descriptions of typed feature structures for representing categories and their parts, while DCGs use first-order terms (or possibly cyclic variants thereof). The second primary difference is that ALE uses a bottom-up active chart parser rather than encoding grammars direclty as Prolog clauses and evaluating them top-down and depth-first. In the spirit of DCGs, ALE allows definite clause procedures to be attached and evaluated at arbitrary points in a phrase structure rule, the difference being that these rules are given by definite clauses in ALE's logic programming system, rather than directly in Prolog.
Phrase structure grammars come with two basic components, one for describing lexical entries, and one for describing grammar rules. We consider these components in turn, after a discussion of the parsing algorithm.
It is not necessary to fully understand the parsing algorithm employed by ALE to exploit its power for developing grammars. But for those users concerned with efficiency and writing grammars with procedural attachments, it is crucial information.
The ALE system employs a bottom-up active chart parser which has been tailored to the implementation attribute-value grammars in Prolog. The single most important fact to keep in mind is that rules are evaluated from left to right. Most of the implementational considerations follow from this rule evaluation principle and its specific implementation in Prolog.
The chart is filled in using a combination of depth- and breadth-first control. In particular, the edges are filled in from right to left, even though the rules are evaluated from left to right. Furthermore, the parser proceeds breadth-first in the sense that it incrementally moves through the string from right to left, one word at a time, recording all of the inactive edges that can be created beginning from the current left-hand position in the string. For instance, in the string The kid ran yesterday, the order of processing is as follows. First, lexical entries for yesterday are looked up, and entered into the chart as inactive edges. For each inactive edge that is added to the chart, the rules are also fired according to the bottom-up rule of chart parsing. But no active edges are recorded. Active edges are purely dynamic structures, existing only locally to exploit Prolog's copying and backtracking schemes. The benefit of parsing from right to left is that when an active edge is proposed by the bottom-up rule, every inactive edge it might need to be completed has already been found. The real reason for the right to left parsing strategy is to allow the active edges to be represented dynamically, while still evaluating the rules from left to right. While the overall strategy is bottom-up, and breadth-first insofar as it steps incrementally through the string, filling in every possible inactive edge as it goes, the rest of the processing is done depth-first to keep as many data structures dynamic as possible, to avoid copying other than that done by Prolog's backtracking mechanism. In particular, lexical entries, the bottom-up rule, and the active edges are all evaluated depth-first, which is perfectly sound, because they all start at the same left point (that before the current word in the right to left pass through the string), and thus do not interact with one another.
Rules can incorporate definite clause goals before, between or after category specifications. These goals are evaluated when they are found. For instance, if a goal occurs between two categories on the right hand side of a rule, the goal is evaluated after the first category is found, but before the second one is. The goals are evaluated by ALE's definite clause resolution mechanism, which operates in a depth-first manner. Thus care should be taken to make sure the required variables in a goal are instantiated before the goal is called. The resolution of all goals should terminate with a finite (possibly empty) number of solutions, taking into account the variables that are instantiated when they are called.
The parser will terminate after finding all of the inactive edges derivable from the lexical entries and the grammar rules. As things stand, ALE does not keep track of the parse tree. Of course, if the grammar is such that an infinite number of derivations can be produced, ALE will not terminate. Such an infinite number of derivations can creep in either through recursive unary rules or through the evaluation of goals.
The current version of ALE has no mechanism for detecting
duplicate edges. Thus there is no mechanism to prevent the
propagation of spurious ambiguities through the parse. A category C
spanning a given subsequence is said to be spurious if there is
another category 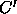 spanning the same subsequence such that C is
subsumed by
spanning the same subsequence such that C is
subsumed by 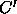 . Only the most general category needs to be recorded
to ensure soundness. Furthermore, it might be the case that there is
redundancy, in the sense that there are two derivations of the same
category. ALE is also unable to detect this situation. This
strategy was followed rather than the standard one which checks for
subsumption when an edge is added, because it was felt that most
grammars do not have any spurious ambiguity. Most unification-based
grammars incorporate some notion of thematic or functional structure
representing the meaning of a sentence. In these cases, most
structural ambiguities result in semantic ambiguities. Thus it would
actually slow the algorithm down to constantly check for a condition
that never occurs. Future versions of ALE should allow the user
to set a flag which determines whether spurious ambiguity and
redundancy is captured during parsing.
. Only the most general category needs to be recorded
to ensure soundness. Furthermore, it might be the case that there is
redundancy, in the sense that there are two derivations of the same
category. ALE is also unable to detect this situation. This
strategy was followed rather than the standard one which checks for
subsumption when an edge is added, because it was felt that most
grammars do not have any spurious ambiguity. Most unification-based
grammars incorporate some notion of thematic or functional structure
representing the meaning of a sentence. In these cases, most
structural ambiguities result in semantic ambiguities. Thus it would
actually slow the algorithm down to constantly check for a condition
that never occurs. Future versions of ALE should allow the user
to set a flag which determines whether spurious ambiguity and
redundancy is captured during parsing.
Lexical entries in ALE are specified as rewriting rules, as given by the following BNF syntax:
<lex_entry> ::= <word> ---> <desc>.For instance, in the categorial grammar lexicon in the appendix, the following lexical entry is provided, along with the relevant macros:
john --->
@ pn(j).
pn(Name) macro
synsem: @ np(Name),
@ quantifier_free.
np(Ind) macro
syn:np,
sem:Ind.
quantifier_free macro
qstore:[].
Read declaratively, this rule says that the word john has as its
lexical category the most general satisfier of the description
@ pn(j), which is:
cat
SYNSEM basic
SYN np
SEM j
QSTORE e_list
Note that this lexical entry is equivalent to that given without
macros by:
john --->
synsem:(syn:np,
sem:j),
qstore:e_list.
Macros are useful as a method of organizing lexical information to
keep it consistent across lexical entries. The lexical entry for the
word runs is:
runs ---> @ iv((run,runner:Ind),Ind).
iv(Sem,Arg) macro
synsem:(backward,
arg: @ np(Arg),
res:(syn:s,
sem:Sem)),
@ quantifier_free.
This entry uses nested macros along with structure sharing, and
expands to the category:
cat
SYNSEM backward
ARG synsem
SYN np
SEM [0] sem_obj
RES SYN s
SEM run
RUNNER [0]
QSTORE e_list
It also illustrates how macro parameters are in fact treated as
variables.
Multiple lexical entries may be provided for each word. Disjunctions may also be used in lexical entries. Thus the first three lexical entries, taken together, are identical to the fourth:
bank --->
syn:noun,
sem:river_bank.
bank --->
syn:noun,
sem:money_bank.
bank --->
syn:verb,
sem:roll_plane.
bank --->
( syn:noun,
sem:( river_bank
; money_bank
)
; syn:verb,
sem:roll_plane
).
Note that this last entry uses the standard Prolog layout conventions
of placing each conjunct and disjunct on its own line, with commas at
the end of lines, and disjunctions set off with vertically aligned
parentheses at the beginning of lines.
The compiler finds all the most general satisfiers for lexical entries at compile time, reporting on those lexical entries which have unsatisfiable descriptions. In the above case of bank, the second combined method is marginally faster at compile-time, but their run-time performance is identical. The reason for this is that both entries have the same set of most general satisfiers.
ALE supports the construction of large lexicons, as it relies on Prolog's hashing mechanism to actually look up a lexical entry for a word during bottom-up parsing. Constraints on types can also be used to enforce conditions on lexical representations, allowing for further factorization of information.
ALE allows the user to specify certain categories as occurring without any corresponding surface string. These are usually referred to somewhat misleadingly as empty categories, or sometimes as null productions. In ALE, they are supported by a special declaration of the form :
empty <desc>.Where <desc> is a description of the empty category.
For example, a common treatment of bare plurals is to hypothesize an empty determiner. For instance, consider the contrast between the sentences kids overturned my trash cans and a kid overturned my trash cans. In the former sentence, which has a plural subject, there is no corresponding determiner. In our categorial grammar, we might assume an empty determiner with the following lexical entry (presented here with the macros expanded):
empty @ gdet(some).
gdet(Quant) macro
synsem:(forward,
arg:(syn:(n,
num:plu),
sem:(body:Restr,
ind:Ind)),
res:(syn:(np,
num:plu),
sem:Ind),
qstore:[ (Quant,
var:Ind,
restr:Restr) ].
Of course, it should be noted that this entry does not match the
type system of the categorial grammar in the appendix, as it assumes a
number feature on nouns and noun phrases.
Empty categories are expensive to compute under a bottom-up parsing
scheme such as is used in ALE. The reason for this is that
these categories must be inserted at every position in the chart
during parsing (with the same begin and end points). If the empty
categories cause local structural ambiguities, parsing will be slowed
down accordingly as these structures are calculated and then
propagated. Consider the empty determiner given above. It will
produce an inactive edge at every node in the chart, then match the
forward application rule scheme and search every edge to its right
looking for a nominal complement. Because there are relatively few
nouns in a sentence, not many noun phrases will be created by this
rule and thus not many structural ambiguities will propagate. But in
a sentence such as the kids like the toys, there will be an edge
spanning kids like the toys corresponding to an empty determiner
analysis of kids. The corresponding noun phrase created
spanning toys will not propagate any further, as there is no way
to combine a noun phrase with the determiner the. But now
consider the empty slash categories of form 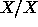 in GPSG.
These categories, when coupled with the slash passing rules, would
roughly double parsing time, even for sentences that can be analyzed
without any such categories. The reason is that these empty
categories are highly underspecified and thus have many options for
combinations. Thus empty categories should be used sparingly, and
prefarably in environments where their effects will not propagate.
in GPSG.
These categories, when coupled with the slash passing rules, would
roughly double parsing time, even for sentences that can be analyzed
without any such categories. The reason is that these empty
categories are highly underspecified and thus have many options for
combinations. Thus empty categories should be used sparingly, and
prefarably in environments where their effects will not propagate.
Another word of caution is in order concerning empty categories: they
can occur in constructions with other empty categories. For instance,
if we specify categories 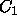 and
and 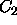 as empty categories, and
have a rule that allows a C to be constructed from a
as empty categories, and
have a rule that allows a C to be constructed from a 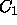 and a
and a
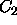 , then C will act as an empty category, as well. These
combinations of empty categories are computed at run-time, and may be
a processing burden if they apply too productively. Keep in mind that
ALE computes all of the inactive edges that can be produced from
a given input string, so there is no way of eliminating the extra work
produced by empty categories interacting with other categories,
including empty ones.
, then C will act as an empty category, as well. These
combinations of empty categories are computed at run-time, and may be
a processing burden if they apply too productively. Keep in mind that
ALE computes all of the inactive edges that can be produced from
a given input string, so there is no way of eliminating the extra work
produced by empty categories interacting with other categories,
including empty ones.
There is a significant restriction on the use of empty categories in ALE. Even though empty categories are copied into the chart, if a rule involves more than one instance of an empty category, spanning the same portion of the chart, it is not guaranteed to work. For instance, if the categories a and b are declared to be empty, and there is a grammar rule such as c --> a, b, then it is not guaranteed that c will be constructed. On the other hand, if the rule is c --> a, d, b, and if d is not empty, then the rule will function normally; it is only the use of two contiguous empty categories in a rule that causes problems. This problem could be worked around at compile-time, but would require significant rewriting of both the lexical processor and the parser.
Lexical rules provide a mechanism for expressing redundancies in the lexicon, such as the kinds of inflectional morphology used for word classes, derivational morphology as found with suffixes and prefixes, as well as zero-derivations as found with detransitivization, nominalization of some varieties and so on. The format ALE provides for stating lexical rules is similar to that found in both PATR-II and HPSG.
In order to implement them efficiently, lexical rules, as well as their effects on lexical entries, are compiled in much the same way as grammars. To enhance their power, lexical rules, like grammar rules, allow arbitrary procedural attachment with ALE definite constraints.
The lexical rule system of ALE is productive in that it allows lexical rules to apply sequentially to their own output or the output of other lexical rules. Thus, it is possible to derive the nominal runner from the verb run, and then derive the plural nominal runners from runner, and so on. At the same time, the lexical system is leashed to a fixed depth-bound, which may be specified by the user. This bound limits the number of rules that can be applied to any given category. The bound on application of rules is specified by a command such as the following, which should appear line initially somewhere in the input file :
:-lex_rule_depth(2).Of course, bounds other than 2 can be used. The bound indicates how many applications of lexical rules can be made, and may be 0. If there is more than one such specification in an input file, the last one will be the one that is used.
The format for lexical rules is as follows :
<lex_rule> ::= <lex_rule_name> lex_rule <lex_rewrite>
morphs <morphs>.
<lex_rewrite> ::= <desc> **> <desc>
| <desc> **> <desc> if <goal>
<morphs> ::= <morph>
| <morph>, <morphs>
<morph> ::= (<string_pattern>) becomes (<string_pattern>)
| (<string_pattern>) becomes (<string_pattern>)
when <prolog_goal>
<string_pattern> ::= <atomic_string_pattern>
| <atomic_string_pattern>, <string_pattern>
<atomic_string_pattern> ::= <atom>
| <var>
| <list(<var_char>)>
<var_char> ::= <char>
| <var>
An example of a lexical rule with almost all of the bells and whistles
(we put off procedural attachment for now) is:
plural_n lex_rule
(n,
num:sing)
**> (n,
num:plu)
morphs
goose becomes geese,
[k,e,y] becomes [k,e,y,s],
(X,man) becomes (X,men),
(X,F) becomes (X,F,es) when fricative(F),
(X,ey) becomes (X,[i,e,s]),
X becomes (X,s).
fricative([s]).
fricative([c,h]).
fricative([s,h]).
fricative([x]).
We will use this lexical rule to explain the behavior of the lexical
rule system. First note that the name of a lexical rule, in this case
plural_n, must in general be a Prolog atom. Further note that
the top-level parentheses around both the descriptions and the
patterns are necessary. If the Prolog goal, in this case
fricative(F), had been a complex goal, then it would need to be
parenthesized as well. The next thing to note about the lexical rule
is that there are two descriptions --- the first describes the input
category to the rule, while the second describes the output category.
These are arbitrary descriptions, and may contain disjunctions,
macros, etc. We will come back to the clauses for fricative/1
shortly. Note that the patterns in the morphological component are
built out of variables, sequences and lists. Thus a simple rewriting
can be specified either using atoms as with goose above, with a
list, as in [k,e,y], or with a sequence as in (X,man), or
with both, as in (X,[i,e,s]). The syntax of the morphological
operations is such that in sequences, atoms may be used as a shorthand
for lists of characters. But lists must consist of variables or
single characters only. Thus we could not have used (X,[F]) in
the fricative case, as F might is itself a complex list such as
[s,h] or [x]. But in general, variables ranging over
single characters can show up in lists.
The basic operation of a lexical rule is quite simple. First, every lexical entry, including a word and a category, that is produced during compilation, is checked to see if its category satisfies the input description of a lexical rule. If it does, then a new category is generated to satisfy the output description of the lexical rule, if possible. Note that there might be mutliple solutions, and all solutions are considered and generated. Thus multiple solutions to the input or output descriptions lead to multiple lexical entries.
After the input and output categories have been computed, the word of the input lexical entry is fed through the morphological analyzer to produce the corresponding output word. Unlike the categorial component of lexical rules, only one output word will be constructed, based on the first input/output pattern that is matched.
 The input word is matched against the patterns on the left hand side
of the morphological productions. When one is found that the input
word matches, any condition imposed by a when clause on the
production is evaluated. This ordering is imposed so that the Prolog
goal will have all of the variables for the input string instantiated.
At this point, Prolog is invoked to evaluate the when clause.
In the most restricted case, as illustrated in the above lexical rule,
Prolog is only used to provide abbreviations for classes. Thus the
definition for fricative/1 consists only of unit clauses. For
those unfamiliar with Prolog, this strategy can be used in general for
simple morphological abbreviations. Evaluating these goals requires
the F in the input pattern to match one of the strings given.
The shorthand of using atoms for the lists of their characters only
operates within the morphological sequences. In particular, the
Prolog goals do not automatically inherit the ability of the lexical
system to use atoms as an abbreviation for lists, so they have to be
given in lists. Substituting fricative(sh) for
fricative([s,h]) would not yield the intended interpretation.
Variables in sequences in morphological productions will always be
instantiated to lists, even if they are single characters. For
instance, consider the lexical rule above with every atom written out
as an explicit list:
The input word is matched against the patterns on the left hand side
of the morphological productions. When one is found that the input
word matches, any condition imposed by a when clause on the
production is evaluated. This ordering is imposed so that the Prolog
goal will have all of the variables for the input string instantiated.
At this point, Prolog is invoked to evaluate the when clause.
In the most restricted case, as illustrated in the above lexical rule,
Prolog is only used to provide abbreviations for classes. Thus the
definition for fricative/1 consists only of unit clauses. For
those unfamiliar with Prolog, this strategy can be used in general for
simple morphological abbreviations. Evaluating these goals requires
the F in the input pattern to match one of the strings given.
The shorthand of using atoms for the lists of their characters only
operates within the morphological sequences. In particular, the
Prolog goals do not automatically inherit the ability of the lexical
system to use atoms as an abbreviation for lists, so they have to be
given in lists. Substituting fricative(sh) for
fricative([s,h]) would not yield the intended interpretation.
Variables in sequences in morphological productions will always be
instantiated to lists, even if they are single characters. For
instance, consider the lexical rule above with every atom written out
as an explicit list:
[g,o,o,s,e] becomes [g,e,e,s,e],
[k,e,y] becomes [k,e,y,s],
(X,[m,a,n]) becomes (X,[m,e,n]),
(X,F) becomes (X,F,[e,s]) when fricative(F),
(X,[e,y]) becomes (X,[i,e,s]),
X becomes (X,[s]).
In this example, the s in the final production is given as a
list, even though it is only a single character.
The morphological productions are considered one at a time until one is matched. This ordering allows a form of suppletion, whereby special forms such as those for the irregular plural of goose and key to be listed explicitly. It also allows subregularities, such as the rule for fricatives above, to override more general rules. Thus the input word beach becomes beaches because beach matches (X,F) with X = [b,e,a] and F = [c,h], the goal fricative([c,h]) succeeds and the word beaches matches the output pattern (X,F,[e,s]), instantiated after the input is matched to ([b,e,a],[c,h],[e,s]). Similarly, words that end in [e,y] have this sequence replaced by [i,e,s] in the plural, which is why an irregular form is required for keys, which would otherwise match this pattern. Finally, the last rule matches any input, because it is just a variable, and the output it produces simply suffixes an [s] to the input.
For lexical rules with no morphological effect, the production:
X becomes Xsuffices. To allow lexical operations to be stated wholly within Prolog, a rule may be used such as the following:
X becomes Y when morph_plural(X,Y)In this case, when morph_plural(X,Y) is called, X will be instantiated to the list of the characters in the input, and as a result of the call, Y should be instantiated to a ground list of output characters.
We finally turn to the case of lexical rules with procedural attachments, as in the following (simplified) example from HPSG:
extraction lex_rule
local:(cat:(head:H,
subcat:Xs),
cont:C),
nonlocal:(to_bind:Bs,
inherited:Is)
**> local:(cat:(head:H,
subcat:Xs2),
cont:C),
nonlocal:(to_bind:Bs,
inherited:[G|Is])
if
select(G,Xs,Xs2)
morphs
X becomes X.
select(X,(hd:X),Xs) if true.
select(X,[Y|Xs],[Y|Ys]) if
select(X,Xs,Ys).
This example illustrates an important point other than the use of
conditions on categories in lexical rules. The point is that even
though only the LOCAL CAT SUBCAT and NONLOCAL INHERITED
paths are affected, information that stays the same must also be
mentioned. For instance, if the cont:C specification had been
left out of either the input our output category description, then the
output category of the rule would have a completely unconstrained
content value. This differs from the defaulty nature of the usual
presentation of lexical rules, which assumes all information that
hasn't been explicitly specified is shared between the input and the
output. As another example, we must also specify that the HEAD
and TO_BIND features are to be copied from the input to the
output; otherwise there would be no specification of them in the
output of the rule. This fact follows from the description of the
application of lexical rules: they match a given category against the
input description and produce the most general category(s) matching
the output description.
Turning to the use of conditions in the above rule, the select/3 predicate is defined so that it selects its first argument as a list member of its second argument, returning the third argument as the second argument with the selected element deleted. In effect, the above lexical rule produces a new lexical entry which is like the original entry, except for the fact that one of the elements on the subcat list of the input is removed from the subcat list and added to the inherited value in the output. Nothing else changes.
Procedurally, the definite clause is invoked after the lexical rule has matched the input description against the input category. Like the morphological system, this control decision was made to ensure that the relevant variables are instantiated at the time the condition is resolved. The condition here can be an arbitrary goal, but if it is complex, there should be parentheses around the whole thing. Cuts should not be used in conditions on lexical rules (see the comments on cuts in grammar rules below, which also apply to cuts in lexical rules).
Currently, ALE does not check for redundancies or for entries that subsume each other, either in the base lexicon or after closure under lexical rules. ALE does not apply lexical rules to empty categories.
Grammar rules in ALE are of the phrase structure variety, with annotations for both goals that need to be solved and for attribute-value descriptions of categories. The BNF syntax for rules is as follows :
<rule> ::= <rule_name> rule <desc> ===> <rule_body>.
<rule_body> ::= <rule_clause>
| <rule_clause>, <rule_body>
<rule_clause> ::= cat> <desc>
| cats> <desc>
| goal> <goal>
The <rule_name> must be a Prolog atom. The description in the
rule is taken to be the mother category in the rule, while the rule
body specifies the daughters in the rule along with any side
conditions on the rule, expressed as an ALE goal. A further
restriction on rules, which is not expressed in the BNF syntax
above, is that there must be at least one category-seeking rule clause
in each rule body.
Thus empty productions are not allowed and will be
flagged as errors at compile time.
A simple example of such a rule, without any goals, is as follows:
s_np_vp rule
(syn:s,
sem:(VPSem,
agent:NPSem))
===>
cat>
(syn:np,
agr:Agr,
sem:NPSem),
cat>
(syn:vp,
agr:Agr,
sem:VPSem).
There are a few things to notice about this rule. The first is that
the parentheses around the category and mother descriptions are
necessary. Looking at what the rule means, it allows the combination
of an np category with a vp type category if they have
compatible (unifiable) values for agr. It then takes the
semantics of the result to be the semantics of the verb phrase, with
the additional information that the noun phrase semantics fills the
agent role.
Even though the parsing proceeds from right to left, rules are evaluated from left to right, so that the descriptions of daughter categories are evaluated in the order in which they are specified. This is significant when considering goals that might be interleaved with searches in the chart for consistent daughter categories.
Unlike the PATR-II rules, but similar to DCG rules, ``unifications'' are specified by variable co-occurrence rather than by path equations, while path values are specified using the colon rather than by a second kind of path equation. The rule above is similar to a PATR-II rule which would look roughly as follows:
x0 ---> x1, x2 if
(x0 syn) == s,
(x1 syn) == np,
(x2 syn) == vp,
(x0 sem) == (x2 sem),
(x0 sem agent) == (x1 sem),
(x1 agr) == (x2 agr)
Unlike lexical entries, rules are not expanded to feature structures at compile-time. Rather, they are compiled down into structure-copying operations involving table look-ups for feature and type symbols, unification operations for variables, sequencing for conjunction, and choice point creation for disjunction. In the case of feature and type symbols, a double-hashing is performed on the type of the structure being added to, as well as either the feature or the type being added. Additional operations arise from type coercions that adding features or types require. Thus there is nothing like disjunctive normal-form conversion of rules at compile time, as there is for lexical entries. In particular, if there is a local disjunction in a rule, it will be evaluated locally at run time. For instance, consider the following rule, which is the local part of HPSG's Schema 1:
schema1 rule
(cat:(head:Head,
subcat:[]),
cont:Cont)
===>
cat>
(Subj,
cat:head:( subst
; spec:HeadLoc,
)),
cat>
(HeadLoc,
cat:(head:Head,
subcat:[Subj]),
cont:Cont).
Note that there is a disjunction in the cat:head value of the
first daughter category (the subject in this case). This disjunction
represents the fact that the head value is either a substantive
category (one of type subst), or it has a specifier value which
is shared with the entire second daughter. But the choice between the
disjuncts in the first daughter of this rule is made locally, when the
daughter category is fully known, and thus does not create needless
rule instantiations.
The cats> operator is used to recognize a list of daughters, whose length cannot be determined until run-time. Daughters recognized as part of a cats> specification are not recognized as quickly, as a result. Note also the interpretation of cats> requires that its argument is subsumed by the type list, which must be defined, along with ne_list, e_list, etc., and the features HD, and TL, which we defined above. This check is not made using unification, so that an underspecified list argument will not work either. If the argument of cats> is not subsumed by list, then the rule in which that argument occurs will never match to any input, and a run-time error message will be given. This operator is useful for so-called ``flat'' rules, such as HPSG's Schema 2, part of which is given (in simplified form) below:
schema2 rule
(cat:(head:Head,
subcat:[Subj]))
===>
cat>
(cat:(head:Head,
subcat:[Subj|Comps])),
cats> Comps.
Since various lexical items have SUBCAT lists of various
lengths, e.g. zero for proper nouns, one for intransitive verbs, two
for transitive verbs, cats> is required in order to match the
actual list of complements at run-time.
It is common to require a goal to produce an output for the argument of cats>. If this is done, the goal must be placed before the cats>. Our use of cats> is problematic in that we require the argument of cats> to evaluate to a list of fixed length. Thus the following head-final version of HPSG's Schema 2 would not work:
schema2 rule
(cat:(head:Head,
subcat:[SubjSyn]))
===>
cats> Comps,
cat>
(cat:(head:Head,
subcat:[Subj|Comps])).
One way to work around this is to post some finite upper bound on the
size of the Comps list by means of a constraint.
... goal> three_or_less(Comps), ... three_or_less([]) if true. three_or_less([_]) if true. three_or_less([_,_]) if true. three_or_less([_,_,_]) if true.The problem with this strategy from an efficiency standpoint is that arbitrary sequences of three categories will be checked at every point in the grammar; in the English case, the search is directed by the types instantiated in Comps as well as that list's length. From a theoretical standpoint, it is impossible to get truly unbounded length arguments in this way.
ALE's general treatment of disjunction in descriptions, which is an extension of Kasper and Round's (1986) attribute-value logic to phrase structure rules, is a vast improvement over a system such as PATR-II, which would not allow disjunction in a rule, thus forcing the user to write out complete variants of rules that only differ locally. Disjunctions in rules do create local choice points, though, even if the first goal in the disjunction is the one that is solvable.
This is because, in general, both parts of a disjunction might be
consistent with a given category, and lead to two solutions. Or one
disjunct might be discarded as inconsistent only when its variables are
further instantiated elsewhere in the rule.
Finally, it should be kept in mind that the mother category description is evaluated for most general satisfiers only after the categories and goals in the body of the rule have been solved.
A more complicated rule, drawn from the categorial grammar in the appendix, and involving a non-trivial goal, is as follows:
backward_application rule
(synsem:Z,
qstore:Qs)
===>
cat>
(synsem:Y,
qstore:Qs1),
cat>
(synsem:(backward,
arg:Y,
res:Z),
qstore:Qs2),
goal>
append(Qs1,Qs2,Qs).
Note that the goal in this rule is sequenced after the two category
descriptions. Consequently, it will be evaluated after categories
matching the descriptions have already been found, thus ensuring in
this case that the variables Qs1 and Qs2 are instantiated.
The append(Qs1,Qs2,Qs) goal is then evaluated by ALE's
definite clause resolution mechanism. All possible solutions to the
goal are found with the resulting instantiations carrying over to the
rule. These solutions are found using the depth-first search built
into ALE's definite constraint resolver. In general, goals may
be interleaved with the category specifications, giving the user
control over when the goals are fired. Also note that goals may be
arbitrary cut-free ALE definite clause goals, and thus may
include disjunctions, conjunctions, and negations. Cuts may occur,
however, within the code for any literal clause specified in a
procedural attachment. The attachments themselves must be cut-free to
avoid the cut taking precedence over the entire rule after
compilation, thus preventing the rule to apply to other edges in the
chart or for later rules to apply. Instead, if cuts are desired in
rules, they must be encapsulated in an auxiliary predicate, which will
restrict the scope of the cut. For instance, in the context of a
phrase structure rule, rather than a goal of the form:
goal>
(a, !, b)
it is necessary to encode this as follows:
goal>
c
where the predicate c is defined by:
c if
(a, !, b).
This prevents backtracking through the cut in the goal, but does not
block the further application of the rule. A similar strategy should
be employed for cuts in lexical rules.
As a programming strategy, rules should be formulated like Prolog clauses, so that they fail as early as possible. Thus the features that discriminate whether a rule is applicable should occur first in category descriptions. The only work incurred by testing whether a rule is applicable is up to the point where it fails.
Just as with PATR-II, ALE is RE-complete (equivalently, Turing-equivalent), meaning that any computable language can be encoded. Thus it is possible to represent undecidable grammars, even without resorting to the kind of procedural attachment possible with arbitrary definite clause goals. With its mix of depth-first and breadth-first evaluation strategies, ALE is not strictly complete with respect to its intended semantics if an infinite number of edges can be generated with the grammar. This situation is similar to that in Prolog, where a declaratively impeccable program might hang operationally.