What are you talking about? Text-to-Image Coreference
People
Chen Kong, Dahua Lin, Mohit Bansal, Raquel Urtasun, Sanja Fidler
Data
Download the SentencesNYUv2 dataset
 Browse Dataset
Browse Dataset- Multi-sentence descriptions, one description per image
- Noun-object alignment ground-truth
Annotations for alignment indicate to which object in the visual scene a noun in a description refers to. Objects are represented with regions (regions are from the NYUv2 dataset).
- Ground-truth for text:
All ground-truth for text was collected by looking at the text alone (and not the images)- Object or scene class of nouns
For each noun in a description that talks about an object or scene class description we annotated its ground-truth class (thus taking into account synonyms, phrases, mis-spelling).
- Coreference resolution
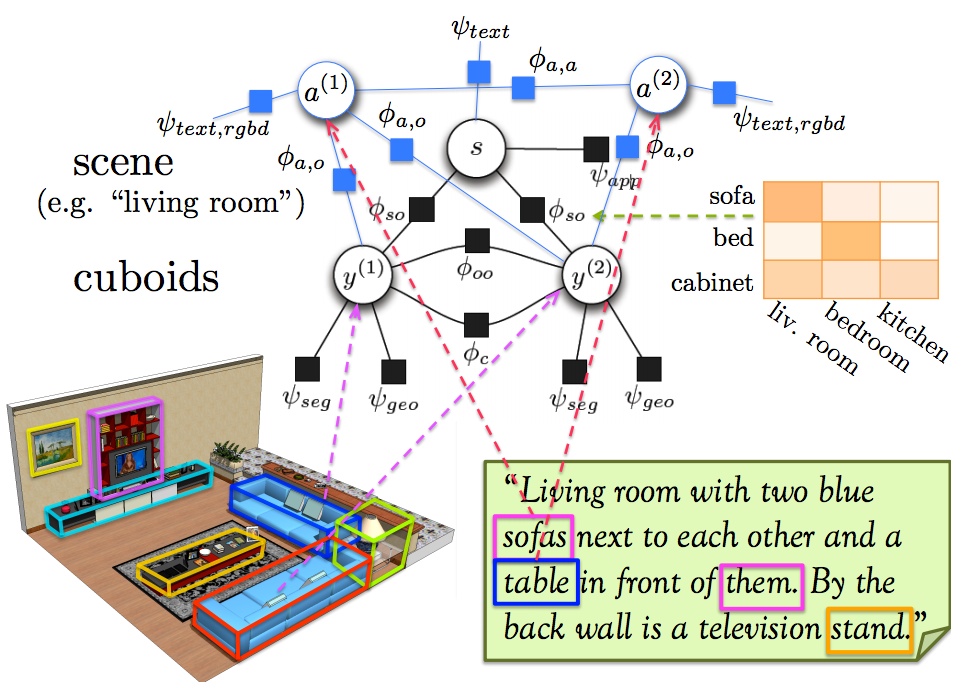
We linked all nouns and pro-nouns that refer to the same physical object in the scene. The coreferal needed to be clear from text alone (since the annotators were not looking at the images).
- Adjectives
We linked all adjectives in a description to the noun that they refer to.
- Prepositions
We annotated all prepositions in a description of the form: noun relation noun noun (last noun is optional)
- Object or scene class of nouns
| Statistics (per description) | |||||
| # sent | # words | min # sent | max # sent | min # words | max # words |
|---|---|---|---|---|---|
3.2 | 39.1 | 1 | 10 | 6 | 144 |
The dataset release includes our annotation tools for both noun-object alignment and text ground-truth collection.
Information about data collection
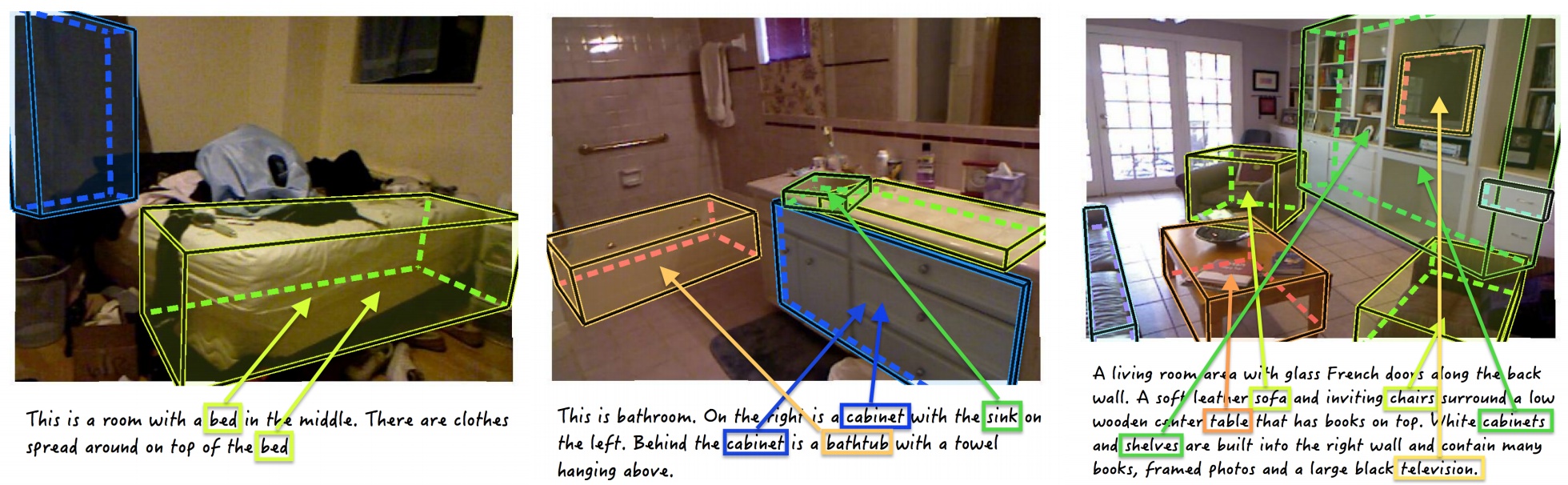
We collected multi-sentence descriptions for the NYUv2 dataset. MTurker was shown an image and was asked to describe it to someone that doesn't see it to give that person a vivid impression of the depicted scene. The Turkers were unconstrained in their descriptions, i.e. they were not asked to mention any specific object or scene class.
In-house annotators then annotated alignments between nouns in the descriptions and regions/objects in the image. For a subset of objects in the scenes we also annotated color labels to enable training object color classifiers. We also collected ground-truth on the text side: in-house annotators were shown only a description and were asked to annotate words that belonged to classes of interests (object and scene classes). We used the class and scene list from our previous work. Annotators were also asked to annotate adjectives referring to a particular noun (all nouns, not just nouns of interest), as well as coreference pairs (words referring to the same physical object in the scene). We also annotated all prepositions in the descriptions.
Contact
For questions regarding the data please contact Sanja Fidler.
Relevant Publications
If you use the data please cite the following publication:
-
What are you talking about? Text-to-Image Coreference
Chen Kong, Dahua Lin, Mohit Bansal, Raquel Urtasun, Sanja Fidler
In Computer Vision and Pattern Recognition (CVPR), Columbus, USA, June, 2014
Exploits text for visual parsing and aligns nouns to objects.
Paper Abstract Bibtex
@inproceedings{KongCVPR14,
title = {What are you talking about? Text-to-Image Coreference},
author = {Chen Kong and Dahua Lin and Mohit Bansal and Raquel Urtasun and Sanja Fidler},
booktitle = {CVPR},
year = {2014}
}In this paper we exploit natural sentential descriptions of RGB-D scenes in order to improve 3D semantic parsing. Importantly, in doing so, we reason about which particular object each noun/pronoun is referring to in the image. This allows us to utilize visual information in order to disambiguate the so-called coreference resolution problem that arises in text. Towards this goal, we propose a structure prediction model that exploits potentials computed from text and RGB-D imagery to reason about the class of the 3D objects, the scene type, as well as to align the nouns/pronouns with the referred visual objects. We demonstrate the effectiveness of our approach on the challenging NYU-RGBD v2 dataset, which we enrich with natural lingual descriptions. We show that our approach significantly improves 3D detection and scene classification accuracy, and is able to reliably estimate the text-to-image alignment. Furthermore, by using textual and visual information, we are also able to successfully deal with coreference in text, improving upon the state-of-the-art Stanford coreference system.