Programming
C/C++, Python, SQL, Bash, JavaScript, debugging, profiling, build systems, and automation.
Systems | Networking | ML Infrastructure
Ph.D. researcher in Computer Science at the University of Toronto.
I work on distributed systems, datacenter networking, stateful migration, and distributed ML training performance. My recent work focuses on building practical systems and testbeds for reasoning about correctness, reliability, and performance under contention.
Focus
C/C++, Python, SQL, Bash, JavaScript, debugging, profiling, build systems, and automation.
Consistency, failure handling, live reconfiguration, replication, and performance under contention.
Load migration, scheduling, SDN control-plane behavior, traffic bottlenecks, and network-aware design.
Distributed training, Ring-All-Reduce bottlenecks, resource scheduling, and cluster simulation.
Backend services, APIs, SQL-backed workflows, dashboards, notification systems, and automation.
My programming background is strongest in systems-oriented C/C++ and Python, with practical experience in SQL, Bash scripting, JavaScript/jQuery, modular design, debugging, profiling, build systems, testing, and automation across research prototypes and backend services.
My systems work is strongest around correctness and performance in live networked systems: state consistency, failure tolerance, state migration, live reconfiguration, resource contention, and reproducible evaluation. This is also supported by Ph.D. coursework in distributed computing and operating systems design.
My networking background covers datacenter load balancing, SDN control-plane migration, TCP/IP and Linux networking concepts, congestion and latency tradeoffs, network-aware scheduling, and simulation/emulation workflows using Mininet and ns-2/ns-3.
My ML systems work focuses on distributed training performance: communication bottlenecks, All-Reduce behavior, network-resource scheduling, data-parallel training concepts, and cluster simulation. This is supported by formal coursework in machine learning and deep learning.
My web and backend experience comes from building production-facing services and internal workflows: Django APIs, PostgreSQL-backed data models, Redis familiarity, JavaScript/jQuery dashboards, push notification logic, campaign tooling, automation, and rollout workflows.
Experience
Designed and evaluated systems for datacenter load balancing, live migration, distributed ML training performance, and state consistency. Built simulation/emulation testbeds, collected metrics, and analyzed performance under failure and contention.
Built backend services and operational workflows for ad management, targeting, delivery, push notifications, publisher script distribution, and internal dashboards.
Supported Operating Systems, Computer Networks, Systems Programming, Networks for ML, and security courses through tutorials, office hours, code review, debugging, and project guidance.
Selected Work
A scheduler for distributed ML training traffic in shared clusters. Foresight coordinates communication across time and network paths to reduce contention and improve training time.
A live migration system for stateful virtual network structures, evaluated with large-scale simulation for latency, buffering, correctness, and migration transparency.
A C++ simulator for large-scale ML clusters that models workloads, transports, topologies, and communication/computation events.
An NFS3-based replicated file-system project using Raft concepts to maintain consistency across server crashes.
Research
IFIP Networking 2025
The rapid growth of Machine Learning workloads has increased reliance on large accelerator clusters, where distributed training jobs demand high-performance network communication.
The rapid growth of Machine Learning (ML) workloads has led to increased reliance on large-scale accelerator clusters, where distributed training jobs demand high-performance network communication. However, the independent execution of ML jobs on shared cluster resources results in network contention, degrading training performance. Existing solutions either focus on optimizing communication operations for isolated jobs or address network scheduling in the time and space dimensions separately, leading to suboptimal outcomes. In this paper, we introduce FORESIGHT, a system that jointly optimizes communication scheduling across both time (when to communicate) and space (where to route traffic) dimensions. By taking advantage of the predictable and repetitive nature of ML training workloads, we can forecast future network demands and better coordinate communication to reduce congestion. Our approach iteratively refines scheduling decisions based on routing feedback, making the optimization problem tractable, while achieving a contention-free schedule. Our extensive evaluations demonstrate that FORESIGHT improves network efficiency, causing up to 46% improvement in ML job iteration times, without requiring modifications to existing network hardware or application frameworks. Our findings emphasize the importance of network-aware scheduling and provide a scalable solution for optimizing distributed ML training in shared cluster environments.
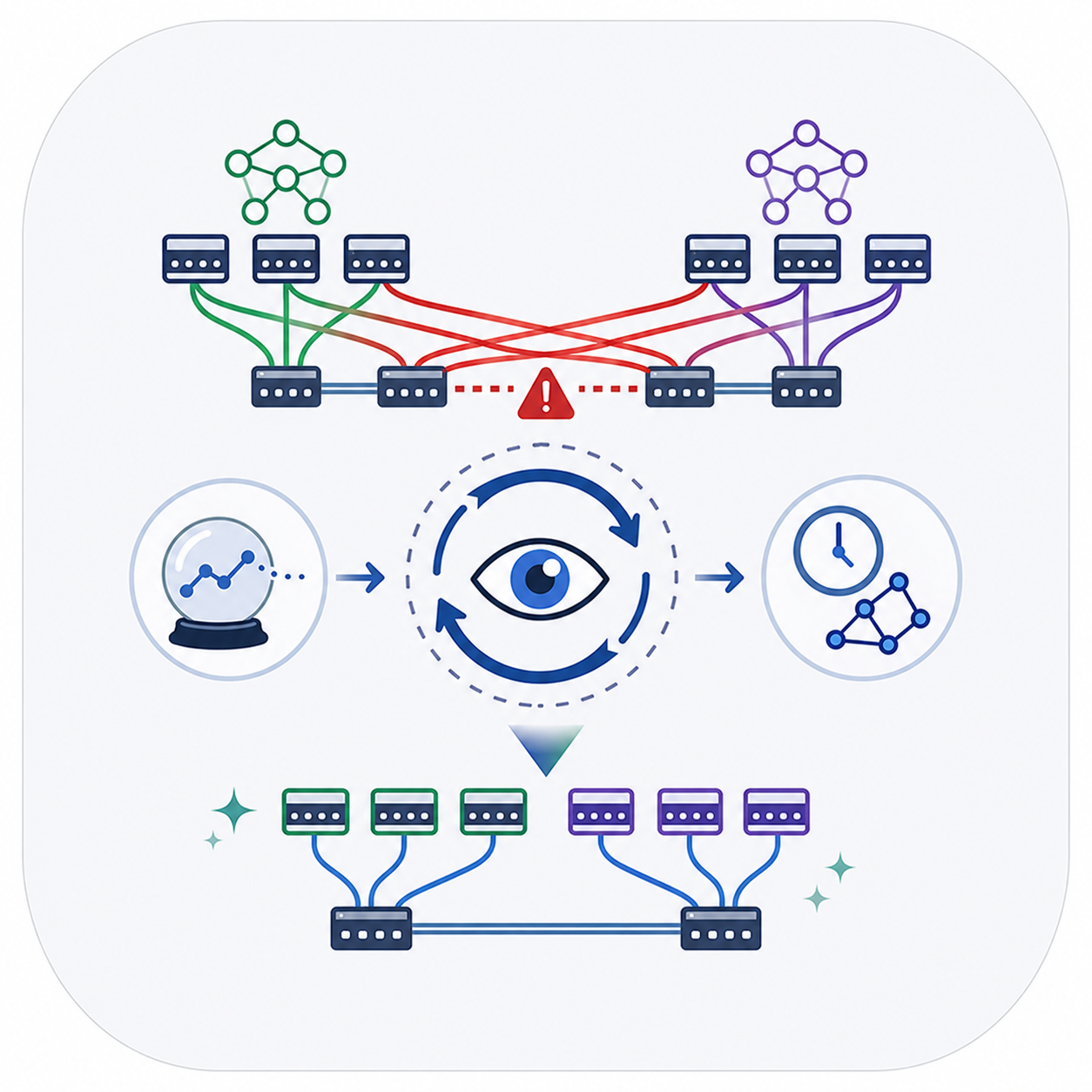
IFIP Networking 2023
Meta-Migration reduces switch migration tail latency by running migration protocols toward multiple candidate destinations and committing based on real-time probes.
Resource management in distributed network control planes plays a vital role in the performance of the data plane and therefore the performance of network applications. Overwhelmed controller instances or underutilized instances could reshape their workloads by exchanging their load, i.e., switches that they control. To safely implement this exchange procedure, switch migration protocols are being used. As the migration procedure pauses processing new flows for a few milliseconds, these protocols are designed to be as fast as possible. Faster protocols add to the agility of the network to rapidly cope with the changing demand. In this paper, we introduce a general framework, called Meta-Migration, which focuses on expediting the existing time-sensitive controller load migration protocols. Based on the observation that these protocols impose low overheads on the involved parties, we modify them in a way that they can run in parallel toward multiple candidate destinations. Unlike the usual Fixed protocols that have to decide their destinations before running the protocol, here we rely on the real-time probes that we obtain from multiple systems and commit to only one of them in the middle of the procedure. Typically, migrations can complete on sub-second timescales, but sudden traffic bursts or system-level glitches can significantly slow down these protocols. We observe that by using Meta-Migration, we can dramatically diminish these negative effects. We show theoretical justifications for why this approach improves the overall performance of the migration, namely, its mean finishing time, and the tail latency of the migration. In addition, by developing a distributed controller simulator over real physical devices, we thoroughly measure the effectiveness of this approach as well as its incurred overheads. Our testbed results show up to a 53% tail reduction in the migration time.
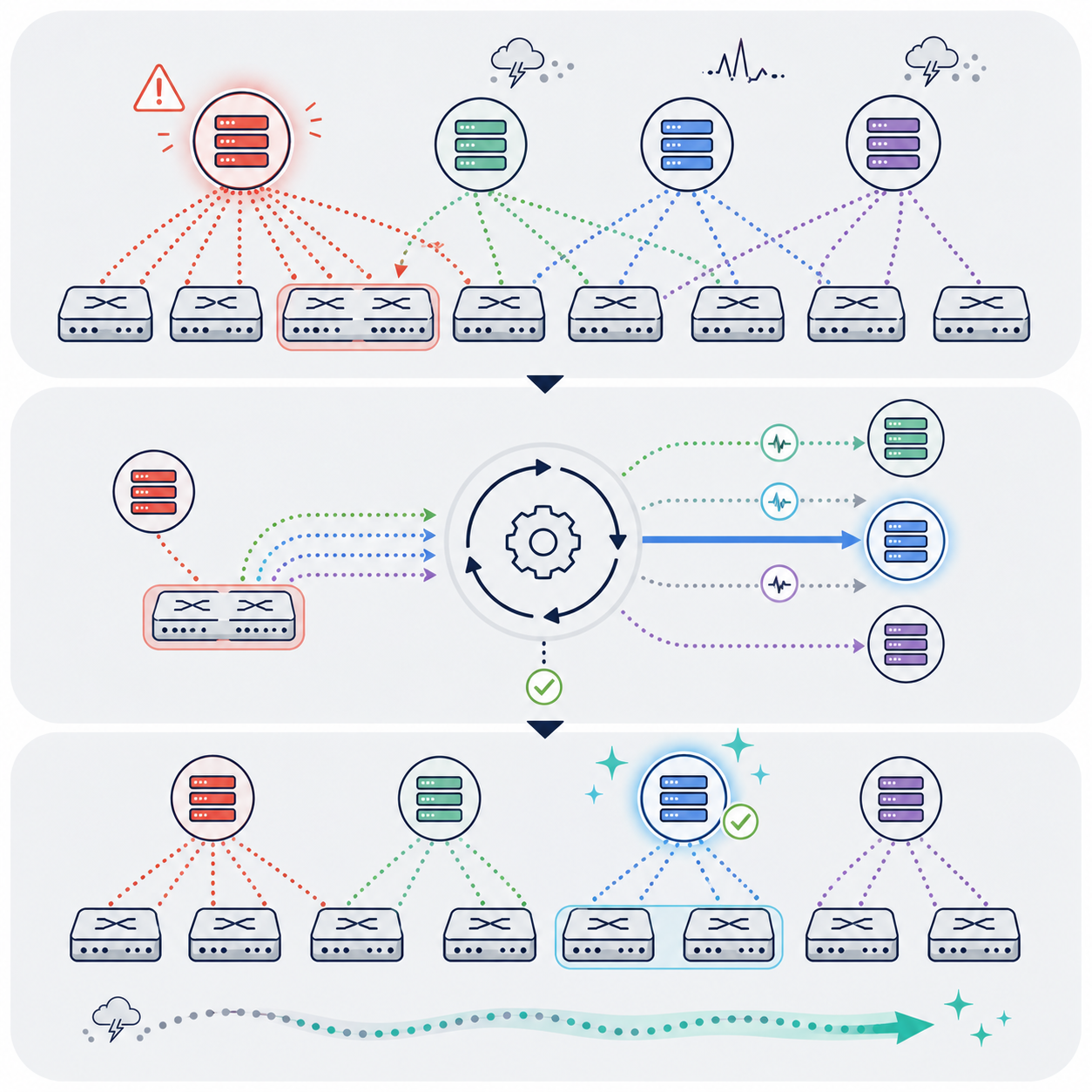
Qanat targets live migration of a stateful virtual sub-network as a whole, preserving active traffic behavior while moving a coordinated network structure.
Traffic processing on cloud-scale bandwidths has given rise to a new type of network structure, comprising a large number of highly-structured virtual entities working in close harmony. This structure, which we call a virtual sub-network, might be in need of migration, for reasons of load-balancing, maintenance, and disaster prevention. In this paper, we argue that the common migration schemes are not adequate for the complexity of this task. Therefore, we present Qanat, a migration system specifically optimized for the live migration of a virtual sub-network in its entirety to a different physical location. We show how Qanat employs widely-used techniques, such as traffic prioritization, buffering, and network tunnels, to overcome the main issues of live migration. In the paper, we categorize the main challenges of the migration task, provide an analytical study of Qanat's algorithms, and measure its performance metrics through large-scale simulations. We conclude that Qanat can efficiently and transparently migrate virtual sub-networks and can provide a useful tool for system administrators.
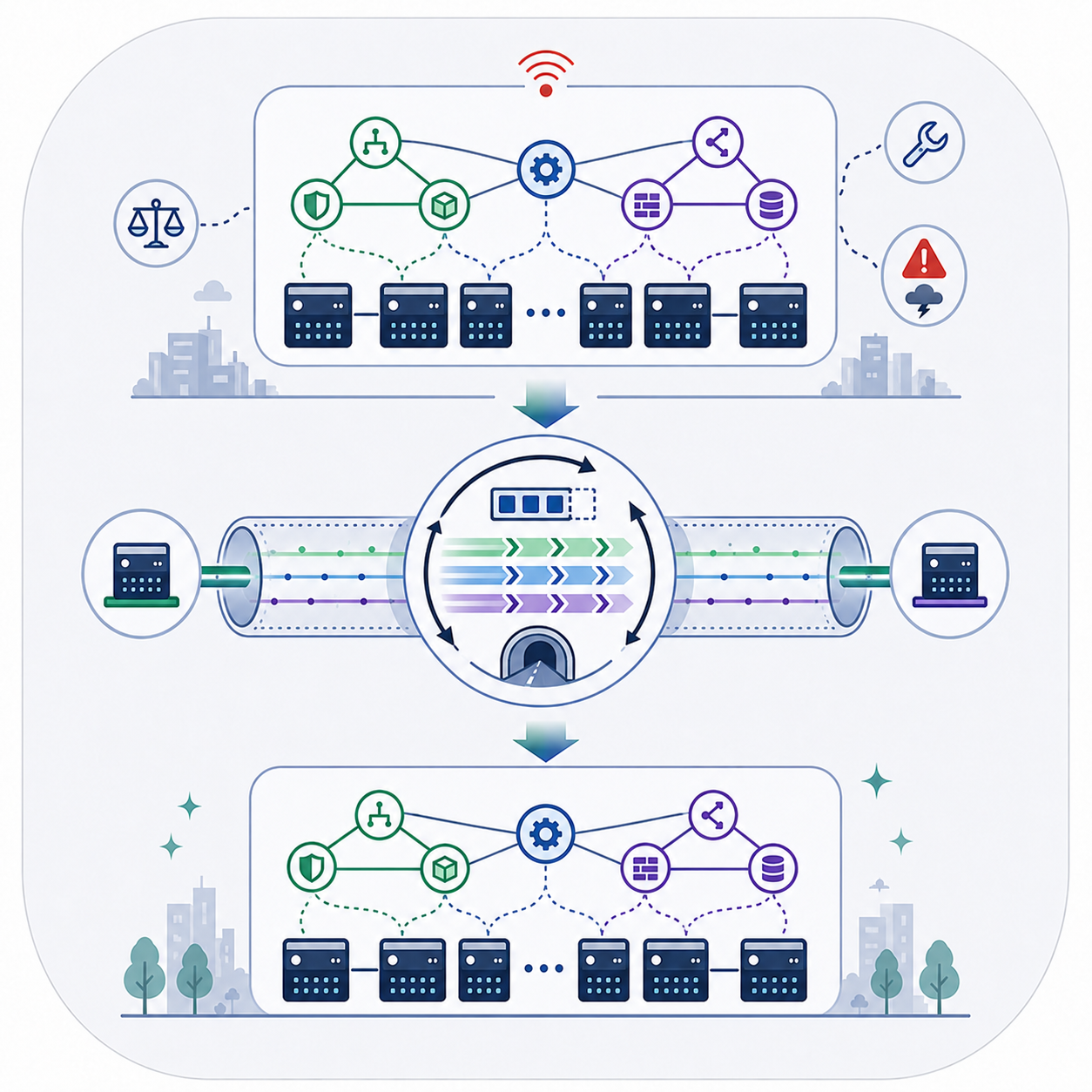
International Journal of Network Management, 2022 (*equal contribution)
ERC migrates switch load between distributed SDN controller instances while preserving resilience, controller consistency, and migration efficiency.
Distributed control solutions were introduced to address controller reliability and scalability issues in software-defined networking (SDN). The dynamic nature of network traffic can lead to load imbalance among controller instances. A highly loaded controller instance can be slow in responding to datapath queries and can slow down the entire control platform, as state synchronization and consensus among controller instances are performed in a cooperative manner. In this paper, we present Efficient, Resilient, Consistent (ERC), a novel protocol for migrating the load of a given switch from a controller instance to a different instance. Our protocol has three distinguishing properties compared with prior works in this area: (1) it is resilient to failures during migration, (2) it maintains consistency among all controller instances, and nevertheless, (3) it is more efficient than existing load migration protocols. Compared with state-of-the-art, ERC reduces the migration time by 23-50% depending on network load. The implicit assumed use case in the design of previous load migration algorithms (including ERC) has been the load balancing scenario. However, as this is not the only possible case, by maintaining the desirable properties of ERC, we introduce four variants of our protocol that can add to the versatility of the load migration handling. This is achieved by considering variations of role exchange between controller instances, which gives us an advantage over the fixed master-slave exchange that vanilla ERC or previous work support. We perform an extensive set of experiments to examine the impact of variable network parameters on the performance metrics of interest and to show the effectiveness of the ERC family of protocols in load migration.
ICCKE 2022 (*equal contribution)
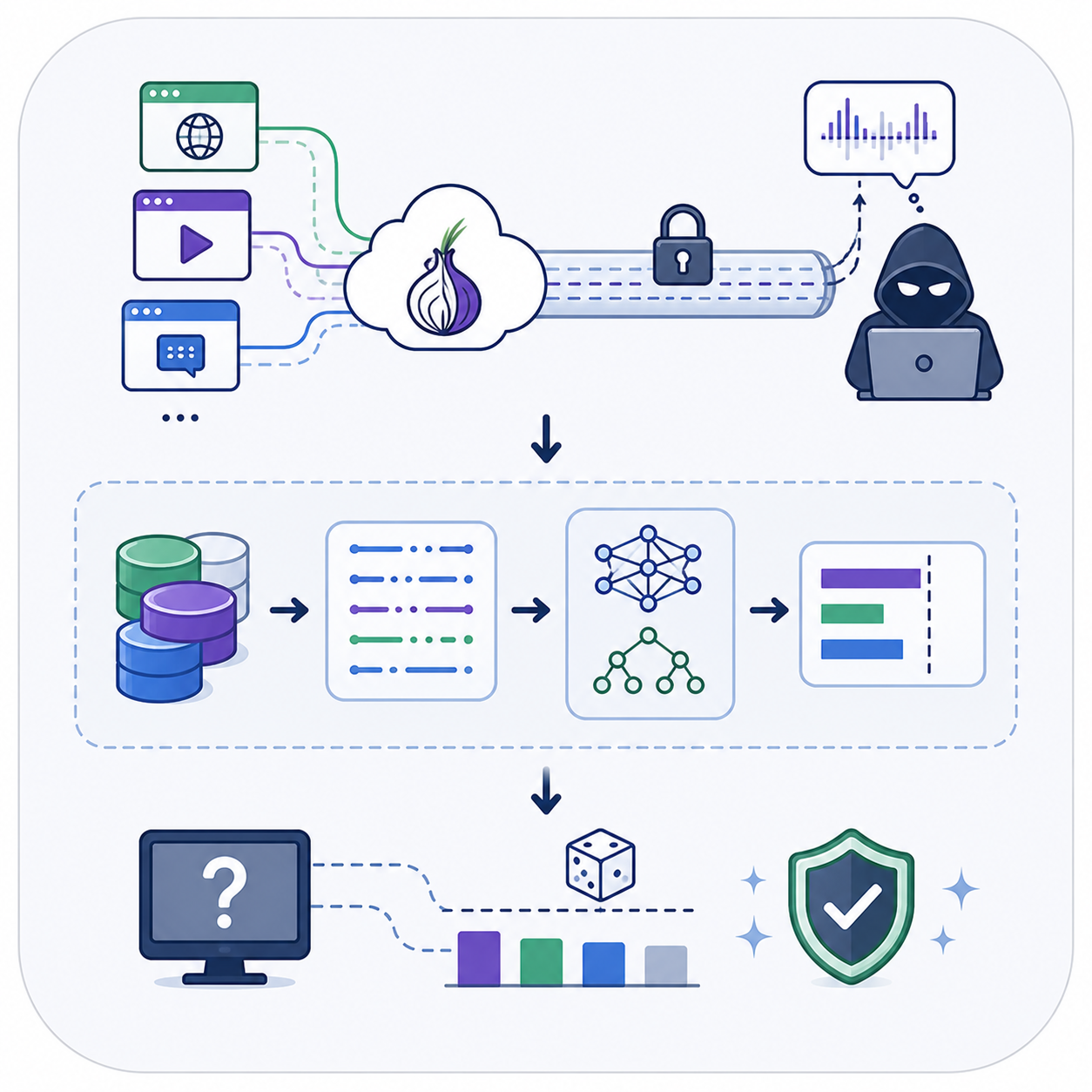
This work studies website fingerprinting attacks on Tor traffic under realistic encrypted mixed-traffic browsing conditions.
This paper studies website fingerprinting attacks on Tor traffic under more realistic browsing conditions than the common single-page experimental setup. The work focuses on identifying websites and applications from heavily encrypted traffic visible to a local eavesdropper, including cases where multiple websites or applications use the Tor proxy at the same time. To build accurately labeled datasets, the authors modified the Tor client and OpenSSL-based traffic handling so Tor cells and network packets could be associated with their destination website or application without decrypting application payloads. The resulting datasets cover multiple user-behavior scenarios, including single-site browsing, simultaneous crawlers, homepage-only visits, and browsing through internal pages. The paper evaluates convolutional neural-network and random-forest classifiers on these traces and reports that, in the studied realistic settings, classification accuracy stays close to random classification. These results suggest that Tor's layered encryption provides strong protection against the evaluated state-of-the-art fingerprinting attacks in realistic mixed-traffic scenarios.
Contact
I am based in Toronto and interested in systems, networking, infrastructure, backend, and ML systems roles.